ReportMiner 7 now offers built-in Optical Character Recognition (OCR). Combined with our sophisticated pattern based text extraction functionality, ReportMiner can be used to unlock data trapped in scanned documents seamlessly.
How does it work in ReportMiner?
ReportMiner uses OCR as a preprocessing step to get the text equivalent of the image found in the scanned pdf documents. Once the equivalent text is available, rest of the process is exactly same as other text based documents. Let’s review the OCR process for PDF documents containing textual information as images:
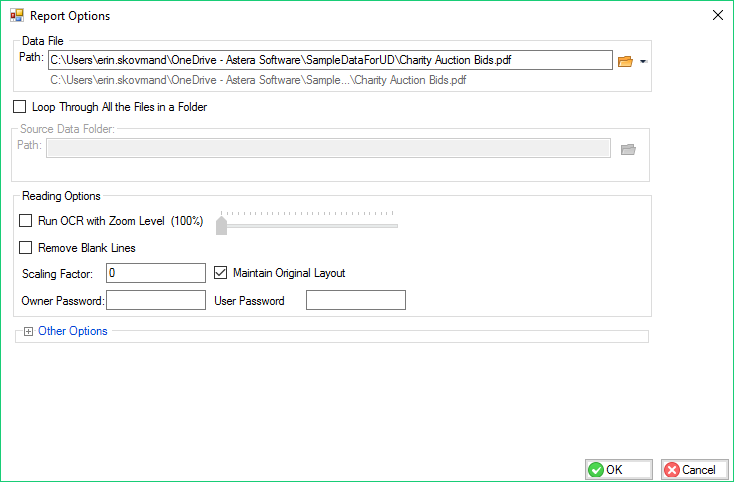
Once we select File > New > Report Model, we can go ahead and set the path to the PDF document containing textual information that we would like to run OCR on.
Make sure that the “Run OCR” option is checked, so that ReportMiner will run OCR on the document.
An important thing to be noted here is the option of zoom level and its default value being set to 100%.
Selecting an appropriate zoom level results in both speed and accuracy. If the image containing text is very small, increasing the image size can result in better text recognition with improved accuracy. Hence, you can adjust this zoom level until you get the desired results.
Below is a screenshot of the PDF document we are trying to read using ReportMiner.

As soon as you select “Ok”, ReportMiner will start running OCR on the document.
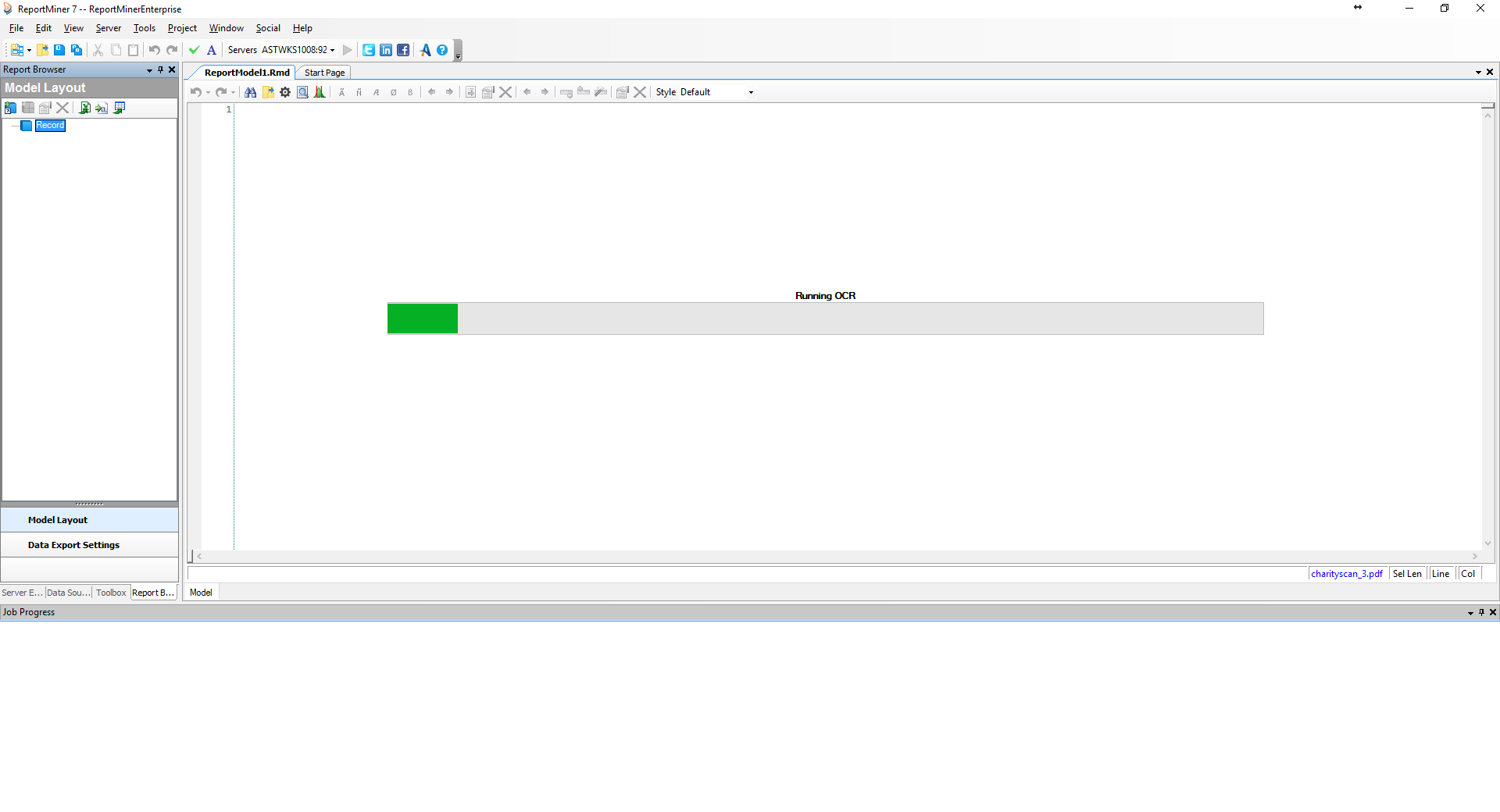
As shown below, Report Miner grabs the textual information from the PDF document and displays it on the screen.
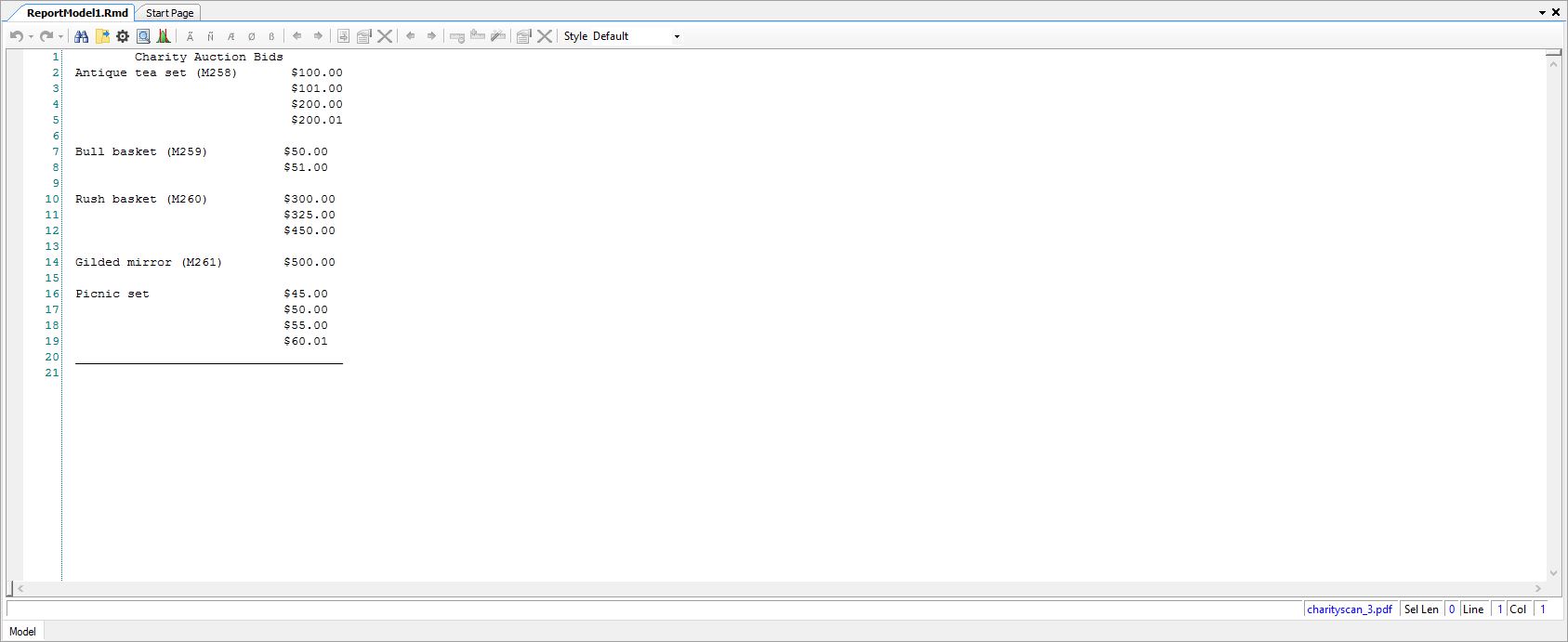
Now that you have your document digitized, it can be processed by ReportMiner. It can be used to create report models to create data regions and identify matching patterns, grab data, and export it to your desired destination.
0 Comments